一.链表的设计
1.节点的创建
节点采用结构来定义,将结构体内部分为数据和指针域
- 数据域:定义节点要存储的数据
- 指针域:定义用来存储下一个节点指针的指针变量(⚠️数据类型用结构体数据类型)
2.节点的连接
要创建多少个节点就创建多少个结构体对象,数据域那里该存什么数据赋什么值,指针域那块将其手动赋值为下一个节点的地址 连接🔗:
- 数据域: 该存什么存什么
- 指针域: 存储下一个节点的指针
#include
struct stu {
//数据域
int age;
char name[30];
//指针域
struct stu *next;
};
int main(void){
/*创建节点*/
//默认都将其next设置为NULL,保证其中任意一个为最后一个都可以结束遍历
struct stu node1 = {18,"lisi",NULL};
struct stu node2 = {19,"lijiu",NULL};
struct stu node3 = {20,"ergou",NULL};
//定义头节点指针,记录第一个节点的地址值
struct stu *head = &node1;
//让节点建立连接
node1.next = &node2;
node2.next = &node3;
}
3.遍历链表
⚠️不要直接操作记录着头结点地址的指针去遍历,这会造成内存泄露,丢失指针
定义一个指针pd指向存储着第一个节点地址的头节点head 之后用while循环,结束条件为pd != NULL 在循环内将pd指向当前遍历到结构体内存储的指针next。实现一个个节点不断下移
关键点: 指向下一个节点的代码pd = pd -> next
代码:
#include
struct stu {
//数据域
int age;
char name[30];
//指针域
struct stu *next;
};
int main(void){
/*创建节点*/
//默认都将其next设置为NULL,保证其中任意一个为最后一个都可以结束遍历
struct stu node1 = {18,"lisi",NULL};
struct stu node2 = {19,"lijiu",NULL};
struct stu node3 = {20,"ergou",NULL};
//定义头节点指针,记录第一个节点的地址值
struct stu *head = &node1;
//让节点建立连接
node1.next = &node2;
node2.next = &node3;
/*节点的遍历*/
//定义一个指针记录头节点的地址(不要直接操作记录头节点的指针)
struct stu *pd = head;
while(pd != NULL){
printf("年龄:%d,名字:%s\n",pd -> age,pd -> name);
//⚠️ 将当前指针指向的地址赋值给当前遍历到结构体内记录的地址
pd = pd -> next;
}
}
二.链表头部插入
头部插入: 即是每次新插入的节点都是从头部插入的,每次新插入的节点都是其所插入链表的第一个
1.大体思路
总之,让
head始终指向第一个节点,next始终指向下一个节点
先定义一个用于指向第一节点的指针head,并将其赋赋初值为NULL
-
不存在链表:
直接将当前创建的节点地址赋值给
head,节点内指向下一个节点的next赋值为NULL -
存在链表:
1.先让当前创建节点指向下一节点地址的指针赋值为
head所指向的值 2.再让head赋值为当前创建节点的地址
2.示例
先让链表中存在node2,尝试将node1插入到链表的第一个
#include
struct stu {
//数据域
int age;
char name[30];
//指针域
struct stu *next;
};
//遍历函数
void bsl(struct stu *head){
struct stu *pd = head;
while(pd != NULL){
printf("age:%d,name:%s\n",pd -> age,pd -> name);
//⚠️ 将当前指针指向的地址赋值给当前遍历到结构体内记录的地址
pd = pd -> next;
}
}
int main(void){
//创建节点
struct stu node1 = {18,"lisi",NULL};
struct stu node2 = {19,"lijiu",NULL};
//定义头节点指针,先指定node2为头节点
struct stu *head = &node2;
/*进行第一个节点插入*/
//判断头节点是否为NULL,进而判断是否存在链表
if(head == NULL){
//不存在,直接将当前插入节点的地址赋值给head(node1)
head = &node1;
}else{
//存在,进行头部插入
//先让插入节点的next记录head,再让head记录当前插入节点的地址
node1.next = head;
head = &node1;
}
bsl(head);
}
**效果:**成功将node1节点插入到链表中
root@My-Pc:/mnt/cPoject/LinkedList# ./HeadInsertion
age:18,name:lisi
age:19,name:lijiu
三.链表的尾部插入
1.大体思路
关键点: 就是要找到尾节点,并将当前插入节点的指针给到尾节点的next,然后其自身的next指向NULL
2.实现
- 第一个节点直接赋值给定义好用来记录头结点的指针
head即可 - 其余节点需要从头节点开始遍历,找到尾节点,并将自己的地址值交尾节点
代码:
尝试将wangwu添加到现有链表的末尾
#include
struct stu {
//数据域
int age;
char name[30];
//指针域
struct stu *next;
};
void bsl(struct stu *head);
int main(void){
//创建节点
struct stu node1 = {18,"lisi",NULL};
struct stu node2 = {19,"lijiu",NULL};
struct stu node3 = {25,"wangwu",NULL};
//定义头节点指针
struct stu *head = &node1;
//先为当前的链表添加一个节点,以测试其是否可以在尾部添加
node1.next = &node2;
/*进行第一个节点插入*/
//判断头节点是否为NULL,进而判断是否存在链表
if(head == NULL){
//不存在,直接将当前插入节点的地址赋值给head(node1)
head = &node1;
}else{
//存在,从头节点开始往下遍历,找到最后一个节点,并将最后一个节点的next,赋值为当前节点的地址值
//定义一个新的指针用于遍历(不能动head)
struct stu *pd = head;
while(pd -> next != NULL){
//让pd指向下一个节点的地址
pd = pd -> next;
}
//遍历完毕,pd就已经是指向最后一个节点了
//让最后一个节点的next指向要插入节点
pd -> next = &node3;//假设要插入的节点是node3
//将插入节点的地址值赋值为NULL
node3.next = NULL;//就是演示流程,上面已经初始化过了,没必要
}
bsl(head);
}
void bsl(struct stu *head){
struct stu *pd = head;
while(pd != NULL){
printf("age:%d,name:%s\n",pd -> age,pd -> name);
//⚠️ 将当前指针指向的地址赋值给当前遍历到结构体内记录的地址
pd = pd -> next;
}
}
效果:
root@My-Pc:/mnt/cPoject/LinkedList# ./TailInsertion
age:18,name:lisi
age:19,name:lijiu
age:25,name:wangwu
四.链表的有序插入
有序插入: 即插入时按照节点中的某个信息进行排序,保证顺序
1.实现
1.定义一个参考值
定义节点中的特定值作为参考值,作为排序的依据 2.定义两个指针
two指针的意义,就是在one指针比较值小于下一节点时,用来确定插入点位置的依据⚠ While循环中两指针的比较运算符是<,下面判断究竟是到末尾退出还是到条件退出的比较运算符是>=
-
one指针从头节点开始,不断下移,并与设定的参考值进行比较 -
two指针用于记录下移比较的那个指针one所指向的上一个节点的地址值
3.插入时机
- 当
one所指向节点的参考值大于下一个节点的对应参考点的值且two无值时,表明在第一个,将插入节点作为头节点 (头部插入) 将其地址值赋值给head,将其next(下节点地址)赋值为之前的头节点 - 当
one所指向节点的参考值大于下一个节点的对应参考点的值且two有值时,将插入节点放到two指针指向节点的下一个 (中部插入) - 当
one所指向的值为NULL,即其后面没有节点时,将插入节点插入到链表尾部 (尾部插入)
2.例子
预先准备有链表,并往链表内添加有数据,后继使用有序插入的函数插入一个25岁和22岁的人
需求: 插入节点时按照学生的年龄为依据进行有序插入
#include
#include
#include
struct stu {
// 数据域
int age;
char name[30];
// 指针域
struct stu *next;
};
//遍历链表的函数
void bsl(struct stu *head) {
//定义头部节点
struct stu *pd = head;
while (pd != NULL) {
printf("age:%d,name:%s\n", pd->age, pd->name);
//⚠️ 将当前指针指向的地址赋值给当前遍历到结构体内记录的地址
pd = pd->next;
}
}
//有序排列的函数
struct stu *OrderedInsertion(struct stu *head, struct stu tmp) {
// 申请空间存储进来的节点
struct stu *node = (struct stu *) calloc(1, sizeof(struct stu));
if (node == NULL) {
perror("calloc");
exit(0);
}
//往申请的空间内填入传入节点
*node = tmp;
//初始化传入节点的next为NULL
node->next = NULL;
/*进行第一个节点插入*/
// 判断头节点是否为NULL,进而判断是否存在链表
if (head == NULL) {
// 不存在,直接将当前插入节点的地址赋值给head(node1)
head = node;
return head;
} else {
/*存在*/
// 定义两个操作指针
struct stu *one = head; // 遍历比较的指针
struct stu *two = NULL; // 记录one的指针
// 进行循环比较排序,和插入点比较大小
//符合年龄排序条件或遍历到最后就退出
while ((one->age < node->age) && (one -> next != NULL)) {
// 大于下一个节点参考值,且其值不为NULL,让one指向下一个节点
two = one;
one = one->next;
}
//对结果进行筛选
if (one->age >= node->age) {
// 头部插入
if (two == NULL) {
// 将node的next赋值为head原指向的第一个节点的值
node->next = head;
// 让head指向新插入的头节点node2
head = node;
} else {
// 中部插入
// 将two指向节点的next改为node2的地址
two->next = node;
// 让插入节点node2的next记录的值修改为one,即下一个节点的地址
node->next = one;
}
} else {
// 到这里就是尾部插入了
// 因为one已经指向null,所以指向其前一个节点的指针two所拥有的值就是最后一个节点的值,直接让尾节点记录插入节点的值即可完成尾部插入
one->next = node;
// 将插入节点的next赋值为NULL,标示链表结尾
node->next = NULL;
}
return head;
}
}
int main(void) {
/*创建节点*/
// 默认都将其next设置为NULL,保证其中任意一个为最后一个都可以结束遍历
struct stu node1 = {18, "lisi", NULL};
struct stu node2 = {19, "lijiu", NULL};
struct stu node3 = {20, "ergou", NULL};
struct stu node4 = {25, "wangwu", NULL};
struct stu node5 = {22, "liangliang", NULL};
// 定义头节点指针,记录第一个节点的地址值
struct stu *head = &node1;
// 让节点建立连接
node1.next = &node2;
node2.next = &node3;
//bsl(head);
//尝试调用函数添加王五
struct stu *newHead = OrderedInsertion(head, node4);
//尝试添加两两
struct stu *Head = OrderedInsertion(newHead, node5);
bsl(Head);
}
结果:
root@My-Pc:/mnt/cPoject/LinkedList# ./OrderedInsertion
age:18,name:lisi
age:19,name:lijiu
age:20,name:ergou
age:22,name:liangliang
age:25,name:wangwu
五.查找链表指定节点
1.实现
1.判断链表是否存在,不存在直接返回没找到 2.使用Strcmp函数去循环匹配遍历到节点内要查找的数据,遍历到就返回找到数据
- 这个需要注意判断循环是否到达最后一个节点了,到了记得退出
2.代码
实现功能: 传入要查找的姓名,返回该姓名所处的节点信息
#include
#include
struct stu {
// 数据域
int age;
char name[30];
// 指针域
struct stu *next;
};
/*遍历的函数*/
void bsl(struct stu *head) {
struct stu *pd = head;
while (pd != NULL) {
printf("age:%d,name:%s\n", pd->age, pd->name);
//⚠️ 将当前指针指向的地址赋值给当前遍历到结构体内记录的地址
pd = pd->next;
}
}
/*根据名字查找节点的函数*/
struct stu *search(struct stu *head, char *name) {
//先判断传入链表是否为存在
if (head == NULL) {
printf("链表不存在");
return NULL;
}
//循环遍历链表,匹配要查找的值,找到或遍历完毕就退出循环
struct stu *pd = head;
while ((strcmp(pd -> name, name) != 0) && (pd->next != NULL)) {
//让pd获取第二个节点的地址值
pd = pd->next;
}
if (strcmp(pd->name, name) == 0) {
//找到的搜索名字对应的节点,对其进行返回
return pd;
}
printf("No Search");
return NULL;
}
int main(void) {
/*创建节点*/
// 默认都将其next设置为NULL,保证其中任意一个为最后一个都可以结束遍历
struct stu node1 = {18, "lisi", NULL};
struct stu node2 = {19, "lijiu", NULL};
struct stu node3 = {20, "ergou", NULL};
/* 预先创建链表 */
// 定义头节点指针,记录第一个节点的地址值
struct stu *head = &node1;
// 让节点建立连接
node1.next = &node2;
node2.next = &node3;
bsl(head);
/* 调用函数搜索ergou */
struct stu *search1 = search(head, "ergou");
//打印找到的内容
printf("Search name:%s age:%d\n",search1 -> name,search1 -> age);
}
**结果:**成功找到了ergou
root@My-Pc:/mnt/cPoject/LinkedList# ./NameSearch
age:18,name:lisi
age:19,name:lijiu
age:20,name:ergou
Search name:ergou age:20
六.删除指定节点
下面的方法只适用于节点存储在堆区的情况,因为其删除用的是free
1.实现
(1)思路
删除一个节点,就将这个节点的上一个节点的指针域的值修改为删除节点的下一个节点的指针,然后释放要删除的节点即可

(2)步骤
- 判断存不存在链表,不存在直接返回"链表不存在"
- 判断要删除的节点是不是头节点,是则将
head = head -> head再释放头节点即可 - 不是头节点,则让这个节点的上一个节点的指针域指向要删除节点的下一个节点,之后释放这个节点即可
(3)代码
假设节点都存储在堆区,即存储在动态内存申请的区域的
实现: 根据传入的ID删除对应的节点
节点结构体:
struct stu {
//数据域
int age;
int id;//学号,用于判断删除对象的
char name[30];
//指针域
struct stu *next;
};
业务代码:
#include
#include
#include
struct stu {
//数据域
int age;
int id;//学号,用于判断删除对象的
char name[30];
//指针域
struct stu *next;
};
/*遍历的函数*/
void bsl(struct stu *head) {
struct stu *pd = head;
while (pd != NULL) {
printf("age:%d,name:%s\n", pd->age, pd->name);
//⚠️ 将当前指针指向的地址赋值给当前遍历到结构体内记录的地址
pd = pd->next;
}
}
struct stu* delete(struct stu *head,int id){
//判断链表是否存在
if(head == NULL){
printf("链表不存在\n");
return head;//没删掉,返回原来的头节点指针
}
/*根据ID查找要删除的节点*/
struct stu *pd = head;//用来移动遍历的指针
struct stu *dp = head;//用来记录遍历指针位置的指针
//当 pd-> == id时,就证明找到了,可以退出了
while((pd -> id != id) && (pd -> next != NULL)){
dp = pd;//记录pd的值
pd = pd -> next;//让pd获取第二个节点的地址值
}
//找到了的情况
if(pd -> id == id){
//要删除的节点是第一个节点
if(pd == head){
//让记录第一个节点的指针指向第一个节点的next,即将第二个节点作为第一个节点
head = head -> next;
//释放第一个节点,这里是假设节点是在堆区的情况
free(pd);//释放要删除的节点
printf("删除了id=%d的数据\n",id);
}else{
/*中间节点或尾节点删除*/
//将上一个节点的next赋为删除节点的下一个节点
dp -> next = pd -> next;
free(pd);//释放待删除节点
//依旧是返回原来的head,因为变动的不是头部,而是链表内部
printf("删除了id=%d的数据\n",id);
}
}else{
//没找到
printf("没有找到要删除的节点\n");
}
return head;
}
int main(void) {
/* 创建节点(使用动态内存分配) */
struct stu *node1 = (struct stu*)malloc(sizeof(struct stu));
struct stu *node2 = (struct stu*)malloc(sizeof(struct stu));
struct stu *node3 = (struct stu*)malloc(sizeof(struct stu));
if (node1 == NULL || node2 == NULL || node3 == NULL) {
printf("Memory allocation failed\n");
return 1;
}
node1->age = 18;
node1->id = 1;
strcpy(node1->name, "lisi");
node1->next = node2;
node2->age = 19;
node2->id = 2;
strcpy(node2->name, "lijiu");
node2->next = node3;
node3->age = 20;
node3->id = 3;
strcpy(node3->name, "ergou");
node3->next = NULL;
struct stu *head = node1;
printf("删除前的数据\n");
bsl(head);
struct stu *pStu = delete(head, 2);
// 更新head指针
head = pStu;
printf("删除后的数据\n");
bsl(head);
}
结果:
root@My-Pc:/mnt/cPoject/LinkedList# ./IdDelete
删除前的数据
age:18,name:lisi
age:19,name:lijiu
age:20,name:ergou
删除了id=2的数据
删除后的数据
age:18,name:lisi
age:20,name:ergou
七.释放整个链表
这一切都建立在这个链表中节点都是存储在节点之上
1.整体思路
就是从头部开始,一个一个的向下遍历,在遍历的同时将head指向下一个节点,并将当前遍历到的节点释放
释放每一个节点前,要让该head指向下一个节点,且最后要为head赋值NULL,避免head指针泄露,无法再次对该链表进行赋值
#include
#include
#include
struct stu {
// 数据域
int age;
int id;
char name[30];
// 指针域
struct stu *next;
};
/*遍历的函数*/
void bsl(struct stu *head) {
struct stu *pd = head;
while (pd != NULL) {
printf("age:%d,name:%s\n", pd->age, pd->name);
//⚠️ 将当前指针指向的地址赋值给当前遍历到结构体内记录的地址
pd = pd->next;
}
}
/*释放链表的代码*/
struct stu *free_link(struct stu *head) {
//判断链表是否存在
if (head == NULL) {
printf("链表不存在");
} else {
struct stu *pb = head;
while (pb != NULL) {
head = pb->next;
free(pb);
pb = head;
}
}
return NULL;
}
int main(void) {
/* 创建节点(使用动态内存分配) */
struct stu *node1 = (struct stu *) malloc(sizeof(struct stu));
struct stu *node2 = (struct stu *) malloc(sizeof(struct stu));
struct stu *node3 = (struct stu *) malloc(sizeof(struct stu));
if (node1 == NULL || node2 == NULL || node3 == NULL) {
printf("Memory allocation failed\n");
return 1;
}
node1->age = 18;
node1->id = 1;
strcpy(node1->name, "lisi");
node1->next = node2;
node2->age = 19;
node2->id = 2;
strcpy(node2->name, "lijiu");
node2->next = node3;
node3->age = 20;
node3->id = 3;
strcpy(node3->name, "ergou");
node3->next = NULL;
struct stu *head = node1;
bsl(head);
/*释放整个链表*/
struct stu *pStu = free_link(head);
printf("释放后的遍历\n");
bsl(pStu);
struct stu *node6 = (struct stu *) malloc(sizeof(struct stu));
node6->age = 18;
node6->id = 1;
strcpy(node6->name, "new");
node6->next = NULL;
//往释放后的链表中再次添加数据
pStu = node6;
printf("添加数据后的遍历\n");
bsl(pStu);
}
七.链表反转
1.实现
**初始:**第一次
pb记录head的下一级节点的指针,head将下一级指针赋值为NULL
进入循环
- pb:永远指向head的下一级节点,每循环一次其位置都会被head取代
head=pb - pn:永远指向pb的下一级节点,每循环一其位置都会被pb取代
pb=pn
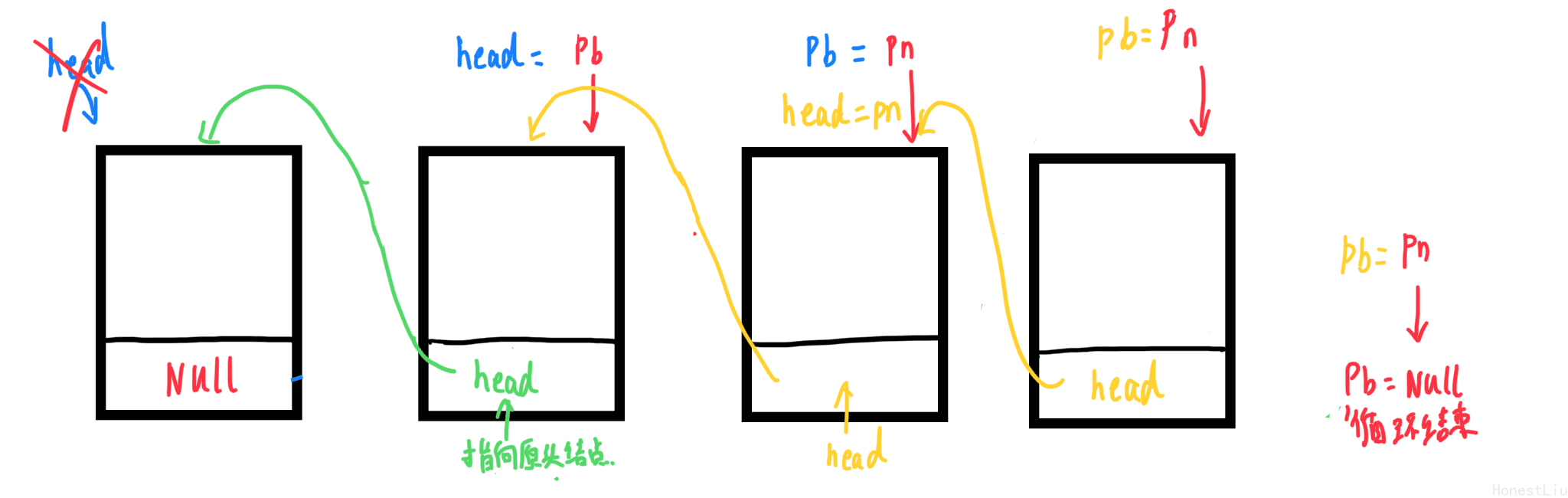
struct stu *reversal(struct stu *head) {
struct stu *pn =NULL;
//记录下初始的head指向的下一个值
struct stu *pb = head -> next;
//让head的指针域变成NULL
head -> next = NULL;
/*不断重复下面的循环,直至pb等于NULL*/
while (pb!= NULL){
//pn记录pb的下一级节点的指针
pn = pb -> next;
//将pb的指针域赋值为head(的地址),让其向下指向变成下一级的head,成为head的上级
pb -> next = head;
//将head赋值为pb,pb位置被head取代
//不要转不过来,就相当于pb节点变成了head节点
head = pb;
//将pb赋值为pn,pb位置被pb取代
//就相当于pn节点变成了pb节点
pb = pn;
}
return head;
}
八.链表排序
实现
需要注意,链表排序如果使用选择排序,必须把最小值计算出来再进行数据交换
且链表的数据交换是包含两部分的,数据和地址
通过选择排序的思想,从0索引开始循环,每循环一次起始索引++一次,每次都将当此循环得到的最小值与循环起始位置的值相交换
每次循环:
因为C语言指针的存在,
min就是指向最小值的指针,无论是交换数据还是交换指针,都可以用这个进行因为我写了太多Java,这点还是有点绕
假设i是最小值,j是i的下一个节点的值,二者不断比较,得出最小值
struct stu *min = i;
j = min->next;
#include
#include
#include
struct stu {
// 数据域
int age;
int id;
char name[30];
// 指针域
struct stu *next;
};
/*遍历的函数*/
void bsl(struct stu *head) {
struct stu *pd = head;
while (pd != NULL) {
printf("age:%d,name:%s\n", pd->age, pd->name);
//⚠️ 将当前指针指向的地址赋值给当前遍历到结构体内记录的地址
pd = pd->next;
}
}
void sort(struct stu *head) {
//使用选择排序的方式,根据ID对链表进行排序
//循环从0索引起始,每循环一次起始索引++一次,每次都将当此循环得到的最小值与循环起始位置的值相交换
struct stu *i = head;//用于记录head地址,保证不丢失,且为了下面的交换数据和地址
struct stu *j = head;
//当i的指针域为空时,间接就是表示其后面已经没有数据了
while (i != NULL) {
//拿i指针所处数据与其后面的所有数据进行比较,将当次循环中的最小值与循环起始位置的值互换位置
struct stu *min = i;
j = min->next;
while (j != NULL) {
if (min->id > j->id) {
//min相当于一个中间值,当i>j,即前一个值大于后一个值时,将这个小的值j赋值给min
min = j;
}
//j向前移
j = j->next;
}
//得到最小值,进行交换
if(i != min){//当i自身不是最小值时才进行交换
//需要注意,下面交换的是数据,用了取值符号
struct stu temp = *i;
*i = *min;
*min = temp;
//将地址交换回来
struct stu *tempNext = i->next;
i->next = min->next;
min->next = tempNext;
}
//每循环一次起始指针前移
i = i->next;
}
}
int main(void) {
/* 创建节点(使用动态内存分配) */
struct stu *node1 = (struct stu *) malloc(sizeof(struct stu));
struct stu *node2 = (struct stu *) malloc(sizeof(struct stu));
struct stu *node3 = (struct stu *) malloc(sizeof(struct stu));
if (node1 == NULL || node2 == NULL || node3 == NULL) {
printf("Memory allocation failed\n");
return 1;
}
node1->age = 18;
node1->id = 2;
strcpy(node1->name, "lisi");
node1->next = node2;
node2->age = 19;
node2->id = 1;
strcpy(node2->name, "lijiu");
node2->next = node3;
node3->age = 20;
node3->id = 3;
strcpy(node3->name, "ergou");
node3->next = NULL;
struct stu *head = node1;
printf("排序前\n");
bsl(head);
printf("排序后\n");
sort(head);
bsl(head);
}
八.typedef
1.用途
- 给结构体起别名
- 创建结构体变量的指针
(1)起别名
总的记住一个原则,先创建遍历再起别名 至于遍历是在创建结构体时创建的,还是后面创建的,都行,都可以用来起别名
方式一: 创建结构体的同时创建一个变量,并用这个变量来起别名
typedef struct stu {
//数据域
int age;
char name[30];
//指针域
struct stu *next;
}DATA;
方式二: 先创建结构体再给其起别名
struct stu {
//数据域
int age;
char name[30];
//指针域
struct stu *next;
};
//起别名
typedef struct stu DATA;
(2)创建结构体遍历指针
⚠️ 不单单只有这一种方式可以创建,你可以用普通的方式创建
简单说就是将变量变成指针变量,这样就可以创建结构体的指针了,就可以用这个指针方便的接受结构体变量了 代码:
typedef struct stu {
//数据域
int age;
char name[30];
//指针域
struct stu *next;
} *DATA_POIN;
使用:
struct stu stu1 = {18,"zhangsan"};
DATA_POIN = &stu1;