Ⅰ.结构体
一.概念
和JavaBean有些类似,都提供了一种封装方式,但需要注意,JavaBean提供的是类,而结构体提供的是一个新的数据类型
**结构体(Structure)**是C语言中一种重要的复合数据类型,它允许用户将不同类型的数据组合成一个单一的数据类型。
-
结构体通常用于表示具有多个属性或字段的数据对象,这些属性或字段可以是不同的数据类型。
-
结构体提供了一种组织和管理这些数据的方式,使得代码更加清晰、易于理解和维护。
二.结构体定义
**前提:**定义结构体之前,必须要先有类型,再根据类名定义结构体(起名字)
结构体定义关键字:struct
1.方式一⭐
**表现:**定义结构体类型(正常定义)
(1)定义
格式:
struct 结构体类型名{
成员列表
};
创建结构体类型变量:
注:定义变量时,变量名左侧是
struct + 结构体类型名
struct 结构体类型名 变量名;
(2)示例
定义了一个stu的结构体类型
struct stu{
char name[20];
int age;
char sex;
};
创建对象
定义了struct stu类型的变量join,其包含三个成员,分别是name、age、sex
struct stu join;
2.方式二(结构体的初始化)
**表现:**定义结构体类型的同时创建结构体变量
(1)定义
格式:
struct 结构体类型名{
成员列表
}结构体变量 1,变量2;
后继也可以再次创建新的变量:
struct 结构体类型名 变量名;
(2)示例
在创建str结构体类型时,一并创建了join、lucy、lihua这三个变量
struct stu{
char name[20];
int age;
char sex;
} join,lucy,lihua;
创建对象(除定义时一定创建的外,也可以继续创建新的)
struct stu Moroans;
3.方式三
**表现:**定义结构体类型时创建变量,并不指定结构体类型名
**特点:**因为没有类型名,所以以后不能定义这个数据结构类型的变量了(只有一并定义的可用)
(1)定义
格式:
struct {
成员列表
}变量1,变量2;
(2)示例
join,lucy,lihua 就是这个结构体类型的全部变量了,后继也无法再行定义了
struct {
char name[20];
int age;
char sex;
} join,lucy,lihua;
4.起别名
(1)概述
**概述:**将一个结构体类型重新起个类型名,用新的类型名替代原先的类型
(2)格式
别名 等价于 typedef struct 结构体类型
typedef struct 结构体类型 {
成员列表
}别名;
(3)示例
定义:
下面的STU就是这个结构体的别名了
typedef struct stu {
char name[20];
int age;
char sex;
}STU;
使用:
可以直接使用别名来定义结构体类型的变量
STU lucy;
三.结构体变量
1.概述
**结构体变量:**是个变量,这个变量是若干个相同或不同数据构成的集合
- 在定义结构体变量之前首先得有结构体类型,然后再定义变量
- 在定义结构体变量的时候,可以顺便给结构体变量赋初值,被称为结构体的初始化
- 初始化结构体变量时,各个成员要按顺序进行初始化
- 不能出现中间有变量没有初始化的情况
2.结构体变量成员引用
(1)格式
① 单级引用
格式:结构体变量.成员名
例子:bob.num = 100
② 多级引用
类比Java中一个类里面还有别的类
**场景:**一个结构体的内部还有一个结构体
格式:结构体变量1.结构体变量2.成员名
例如:lihua.birthday.year = 2024,lihua和birthday分别是两个结构体的变量
3.初始化
(1)说明
针对先定义后初始化的情况
① 简述
-
一般的数据类型,只要直接用
=号赋值即可,包括指针**注:**指针没赋值前是个野指针
-
但字符数组是个例外,它不能直接
=号赋值
② 注意
定义即初始,要按顺序成员顺序进行初始化,中间不能出现未初始化的成员,但后面可以
③ 字符数组的初始化
**前置:**访问成员数组的格式是结构体变量.数组名,这个得到的仅仅只是数组名,即数组首地址,是一个常量不能对其进行赋值
bob.name = "bob" ❌
**字符数组初始化的方法:**使用strcpy将要用来初始化的字符串复制到数组所在的内存区,借以完成初始化
strcpy(bob.name,"bob"); ✔
(2)示例
#include
#include
#pragma warning(disable:4996)
struct date{
int year;
int mon;
int day;
};
typedef struct stu {
char* userName;
char name[20];
int age;
struct date birthday;
}STU;
int main() {
//初始化要按顺序,中间不能缺,但后面可以
/*定义的同时完成初始化*/
STU LiHua = {
"lihua",
"李华",
23
};
//对于多级初始化,最后放到外边
LiHua.birthday.year = 2024;
LiHua.birthday.mon = 2;
LiHua.birthday.day = 11;
/*定义不初始化*/
STU LiSi;
//对于指针,直接用等号赋值即可
LiSi.userName = "lisi";
//对于数组,要用strcpy拷贝到数组所在的内存区
strcpy(LiSi.name, "李四");
LiSi.age = 24;
LiSi.birthday.year = 2024;
LiSi.birthday.mon = 2;
LiSi.birthday.day = 12;
}
四.结构体数组
就是简单的用结构体类型定义的数组,数组内可以存储多个结构体
1.概述
**介绍:**结构体数组是个数组,由若干个相同类型的结构体变量构成的集合
2.格式
struct 结构体类型名:可以用别名替换
定义:struct 结构体类型名 数组名[元素个数];
引用:数组名[索引]
3.示例
#include
#include
#pragma warning(disable:4996)
#include
typedef struct student
{
int num;
char name[20];
float score;
}STU;
STU edu[3] = {
{101,"Lucy",78},
{102,"Bob",59.5},
{103,"Tom",85}
};
int main()
{
int i;
float sum = 0;
for (i = 0; i < 3; i++)
{
sum += edu[i].score;
}
printf("平均成绩为%f\n", sum / 3);
return 0;
}
五.结构体指针
1.概述
(1)介绍
**介绍:**存放结构体的地址的变量,称为结构体指针。和普通指针一样,在64位Windows中,其占用8个字节
(2)注意事项
-
结构体变量的地址编号和其第一个成员的地址编号相同,但指针的类型不同

-
结构体数组的地址就是结构体第0个元素的地址
2.定义
格式:struct 结构体类型名 * 结构体指针变量名;
例子:struct stu * p;
3.访问成员方法
(1)方法
**方法一:**通过取值符还原成其指向的结构体变量来访问
(*p).name
**方法二:**使用->运算符来访问
意思是:p指向的结构体变量的name
p->name
(2)示例
#include
typedef struct student
{
int num;
char name[20];
float score;
}STU;
int main() {
STU edu[3] = {
{101,"Lucy",78},
{102,"Bob",59.5},
{103,"Tom",85}
};
STU* p = &edu[1];
//方式一
printf("(*p).name=%s\n", (*p).name);//Bob
//方式二
printf("p->name =%s\n", p->name);//Bob
return 0;
}
4.应用
(1)保存结构体变量的地址
要对结构体变量进行取址操作
**概述:**用来保存结构体变量的地址,可以在函数中用这个指针去访问结构体变量的成员
typedef struct stu {
int num;
char name[20];
float score;
}STU;
int main()
{
STU* p, lucy;
p = &lucy;
p->num = 101;
strcpy(p->name, "baby");
//p->name="baby";//错误,因为p->name 相当于lucy.name 是个字符数组的名字,是个常量
}
(2)传结构体变量的地址
传入时需要对结构体变量进行取址操作,传入的必须是其的地址
**概述:**将结构体指针当作是函数的形参,使函数可以接收结构体变量,并在函数内操作结构体变量
#include
#include
typedef struct stu {
int num;
char name[20];
float score;
}STU;
void fun(STU* p)
{
//在函数内就可以通过指针p来操作传入的结构体变量
p->num = 101;
(*p).score = 87.6;
strcpy(p->name, "lucy");
}
int main()
{
STU girl;
//传入结构体变量girl
fun(&girl);
printf("%d %s %f\n", girl.num, girl.name, girl.score);
return 0;
}
(3)传结构体数组的地址
传结构体数组无需用
&取址符,其名字就是数组的首地址,直接传即可
**概述:**同样是将结构体指针当作是函数的形参,使函数可以接收结构体变量的数组,并在函数内操纵其内元素
#include
#include
typedef struct stu {
int num;
char name[20];
float score;
}STU;
void fun(STU* p)
{
//在函数内对结构体变量数组中索引1上的数据进行初始化
p[1].num = 101;
(*(p + 1)).score = 88.6;
}
int main()
{
//创建结构体变量数组
STU edu[3];
//传入结构体变量数组
fun(edu);
//打印数组索引1上的数据,看看函数是否能访问并修改数组中元素的数据
printf("%d %f\n", edu[1].num, edu[1].score);
return 0;
}
六.结构体内存分配
1.默认分配规则
(1)规则1-内存开辟的单位
① 概述
Ⅰ.介绍
默认情况下会按照结构体中占字节数最大的数据类型的字节数作为内存开辟的单位(Double除外)
Ⅱ.注意
- 成员的存储是按照结构体中成员的顺序进行的
- 数组可以看作是多个变量,按数组的数据类型计算内存开辟的单位
② 关于Double
无论是那种环境,double型变量,占8字节
如果结构体中最大的数据类型是Double,根据编译器的不同,内存开辟的单位会出现变化
- **情况1:**在vc6.0和Visual Studio中里,以8字节为单位开辟内存
- **情况2:**在Linux 环境gcc里,以4字节为单位开辟内存
③ 常见的值(除Double)
(1)成员中只有char型数据 ,以1字节为单位开辟内存
(2)成员中出现了short int 类型数据,没有更大字节数的基本类型数据,以2字节为单位开辟内存
(3)出现了int float 没有更大字节的基本类型数据的时候以4字节为单位开辟内存
(4)如果出现指针的话,没有占字节数更大的类型的,以4字节为单位开辟内存
④ 演示
当结构体中有char和int两个类型时,因为int的类型最大,所以以Int类型所占字节即4字节为内存开辟的单位,每开辟一次都是4字节
#include
struct stu{
char sex;
int age;
}lucy;
int main()
{
printf("%d\n",sizeof(lucy));
return 0;
}
(2)规则2-字节对齐
附:我在这道个歉,我写不出能够演示字节对齐的代码,不过可以略微参考下③的代码,逻辑差不多
① 概述
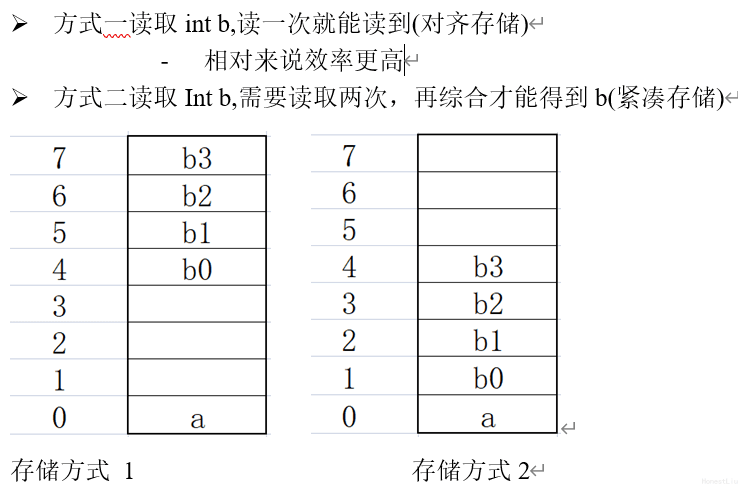
默认情况下,当其要填充的位置不是字节值的倍数,它会用空白符取填充,直至填充到字节值倍数的索引才会存储
**介绍:**字节对齐的值,可以看作是对索引起始值的"限制",数据的存储起始索引必须是字节对齐值的倍数
- 例如int的字节对齐值是4,那它存储的起始索引就只能是4的倍数,如果不是,用空白字符补到是。
注意事项:
- 数组可以看作是多个变量,按数组的数据类型计算字节对齐数
- 开辟内存的时候,从上向下依次按成员在结构体中的位置顺序开辟空间
**作用:**以空间换时间,提高CPU读取数据的效率
- 通过规定字节对齐值,让所有数据都能一次全部读取,无需重复读取,提高效率
② 常见的值
同样的,Doubel类型根据环境的不同,对齐方式也会存在差异
(1):char 1字节对齐 ,即存放char型的变量,内存单元的编号是1的倍数即可。
(2):short int 2字节对齐 ,即存放short int 型的变量,起始内存单元的编号是2的倍数即可。
(3):int 4字节对齐 ,即存放int 型的变量,起始内存单元的编号是4的倍数即可
(4):long int 在32位平台下,4字节对齐 ,即存放long int 型的变量,起始内存单元的编号是4的倍数即可
(5):float 4字节对齐 ,即存放float 型的变量,起始内存单元的编号是4的倍数即可
(6)Double
-
vc6.0和Visual Studio环境下
8字节对齐,即存放double型变量的起始地址,必须是8的倍数,double变量占8字节
-
gcc环境下
4字节对齐,即存放double型变量的起始地址,必须是4的倍数,double变量占8字节。
③ 成员的位置影响所占内存的大小
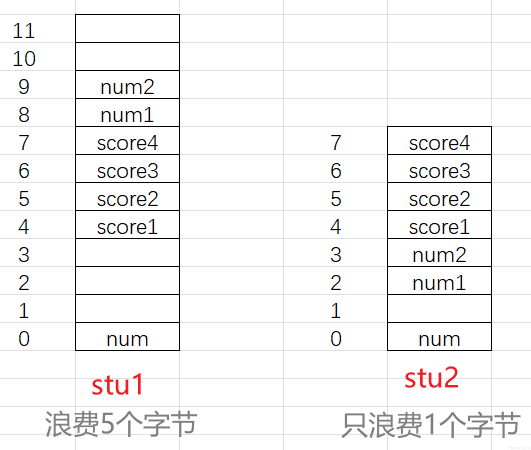
**想讲的:**编写结构体时,要注意不同数据类型成员的顺序,减少空白填充空间的出现
**简述:**当各个成员间的对齐值相差不大时,后一个元素会在前一个元素结束索引附加存储,而不是空出相当大的一片空间
代码:
结构体内的数据所包含的数据类型都相同,仅仅是顺序不同就导致一个占12字节,一个却只占8个字节
#include
struct stu1 {
char num;
int score;
short int num1;
};
struct stu2 {
char num;
short int num1;
int score;
};
int main(int argc, char* argv[])
{
struct stu boy1;
struct stu1 boy2;
printf("%zu\n", sizeof(boy1));//12
printf("%zu\n", sizeof(boy2));//8
return 0;
}
2.指定对齐方式
(1)指定的方法
可以使用#pragma pack改变默认的对齐规则
(2)格式
指定的值必须小于默认值才会生效,否则会取默认值
格式:#pragma pack(value)
-
value:指定对齐的值
- Value的值只能取2的整数倍
(3)影响
下面结论建立在Value生效的基础上
- 会影响字节的对齐方式、
- 所有数据类型都会将value的值作为对齐值
- 会影响内存开辟的单位
- value的值会成为内存开辟的单位
(4)示例
① 设置值小于默认值时
会以设置值2为字节值,以及内存开辟的单位
#include
#pragma pack(2)
struct stu {
char a;
int b;
}temp;
int main()
{
printf("%d\n", sizeof(temp));
printf("%p\n", &(temp.a));
printf("%p\n", &(temp.b));
return 0;
}
**结果:**本来按默认规则会相差3个字节的a和b,设置对齐方式为2后变为相差2个字节
00007FF67C72C1D8
- 00007FF67C72C1DA
------------------
2(二进制)
② 设置值大于默认值时
会以默认规则得出的——4为字节值以及内存开辟的单位
代码:
#include
#pragma pack(8)
struct stu{
char a;
int b;
}temp;
int main()
{
printf("%d\n",sizeof(temp));
printf("%p\n",&(temp.a));
printf("%p\n",&(temp.b));
return 0;
}
**结果:**因为value值大于默认值,所以按照默认值对齐,即a和b相差4个字节
00007FF60892C1D8
- 00007FF60892C1DC
------------------
4(十进制)
3.位段
(1)概述
位其实就是
bit,将对大小的控制精细到了bit,以数据类型的大小作为存储单元,在存储单元的范围内尽可能减少该数据类型的内存占用
① 定义
定义:位段(bit-fields)是C语言中的一种结构体成员,运行指定该成员在内存中所占的位数
② 意义&应用
**意义:**节省存储空间,尤其是当某些数据只需要少量的位来表示时
**应用:**位段常用于需要紧凑存储的数据结构,如硬件控制寄存器、网络通信协议中的位掩码等
② 注意事项
- 位段的大小和布局可能会因为编译器和平台而异
- 位段不能取地址(因为位段可能小于1个字节)
- 位段不能定义数组
- 位段的成员类型必须为整形或字符型
- 赋值时,不能超出位段定义的范围
-
int a:2,最大值为3(看二进制,二进制一位为1bit)
-
- 编译器可能会对位段进行填充(padding)或对齐,这可能会影响到位段的实际存储布局和大小。
(2)定义
位段的设置不能大于该成员数据类型的存储单元大小
位段的声明和定义通常在结构体的定义中进行,通过在成员定义后加冒号:,并在冒号后指定数值来设置位段。
示例:
struct MyStruct {
unsigned int a : 3; // a占据3位
unsigned int b : 5; // b占据5位
};
(3)存储单元
其实就是对应数据类型所占的bit数
| 数据类型 | 存储单元大小 |
|---|---|
char型 |
8位 |
short int型 |
16位 |
int型 |
32位 |
long int型 |
32位 |
(4)存储规则
- 位段成员按照它们在结构体中定义的顺序存储
- 位段的定义不能超过其所属存储单元的大小
- 两个位段的和不足存储单元的大小时,两个位段会被放置在同一个存储单元
- 例如:
char a : 3和char b : 3 - 由于每个位段分别占用3位,而
char类型通常有8位,所以这两个位段都可以存储在同一个char类型的存储单元中。
- 例如:
- 当两个位段的和大于存储单元的大小时,两个位段必须存放在两个不同的存储单元中(不能跨存储单元存储)
- 例如:
char d : 6和char e : 7 - 由于每个位段分别需要6位和7位,加起来总共需要13位,而
char类型只有8位,因此这两个位段不能存储在同一个char类型的存储单元中。
- 例如:
(5)示例
在这个例子中,PackedData结构体总共需要32位(即4字节)的存储空间,即使value成员实际上只用了29位
- **原因:**不能跨存储单元存储的限制
struct PackedData {
unsigned int flag1 : 1; // 1位
unsigned int flag2 : 2; // 2位
unsigned int value : 29; // 29位,总共需要32位(即4字节)的存储空间
};
(6)后注
一些编译器可能会对位段进行填充(padding)或对齐,这可能会改变位段的实际存储布局。因此,在编写涉及到位段的代码时,最好查阅你所使用的编译器的文档,以了解具体的实现细节和行为
Ⅱ.共用体
共用体通常用于低级编程,如硬件编程或嵌入式系统编程,在这些场景中内存管理至关重要。
一.概述
(1)介绍
- 共用体是一种特殊的数据结构,它允许在相同的内存位置存储不同的数据类型
- 与结构体不同,共用体不会为其成员分配独立的内存空间,而是所有成员共享同一块内存区域
- 共用体的大小(内存段)通常等于其成员中最大的数据类型所占用的内存空间
(2)特点
- 同一内存段可以用来存放多种不同类型的成员
- 对共同体的一个成员赋值会覆盖其它成员的值
- 同一时间只能使用一个成员(使用的是最后存入的成员)
- 共用体变量的地址和它的各成员的地址都是同一地址
- 初始化只能对其中的单一成员赋值,不能对所有成员赋值
(3)使用场景
- 当需要存储多种数据类型,但每次只使用其中一种类型时。
- 需要节省内存时。
二.定义
(1)格式
-
union关键字:定义共用体的关键字 -
union_name:共用体的名称 -
data_type1,data_type2, ...,data_typeN是成员的数据类型 -
member1,member2, ...,memberN是成员的名称
union union_name {
data_type1 member1;
data_type2 member2;
// ... 可以有更多的成员
data_typeN memberN;
};
(2)示例
#include
union ExampleUnion {
int integerValue;
float floatingValue;
char character;
};
int main() {
union ExampleUnion value;
value.integerValue = 10; // 内存位置被整数10占据
printf("%d\n", value.integerValue); // 输出10
value.floatingValue = 3.14f; // 内存位置被浮点数3.14f覆盖
printf("%f\n", value.floatingValue); // 输出3.140000
value.character = 'A'; // 内存位置被字符'A'覆盖
printf("%c\n", value.character); // 输出A
// 访问其他成员将显示最后赋值的成员的值,或者是不可预测的结果
printf("%d\n", value.integerValue); // 输出可能是'A'的ASCII值,或者是不确定的值
return 0;
}
Ⅲ.枚举
一.概述
不专业来讲就是给数字取名字
1.看法
简单总结它,就是既节省内存,又提高了代码的阅读性的"数字"。编写和调试时是文字、实际编译后就是其底层得整形数字
- **节省内存:**尽管在编辑、调试阶段它以文字形式显示,但其实际就是一堆整数(int),相较于直接使用宏定义或文本表示,更节省内存
- **提高代码阅读性:**虽然它表示的数字,但在代码中、调试时显示的是文字,方便阅读
2.定义
这些名称在编译后就会变成其代表的那个整数
- 枚举是一种用户定义的数据类型,它允许你为一组整数值指定有意义的名称
- 枚举类型通常用于表示一组相关的常量值
- 例如一周中的天数或颜色等
3.特点
- 枚举成员是常量,它们的值通常是不可变的
- 枚举成员在内存中以整数形式存储,通常是int类型的大小
4.注意事项
- 枚举成员的名称是唯一的,不能重复
- 枚举成员的值必须是整数,不能是浮点数或其他类型
- 主要出现在为枚举成员赋值时(只能在定义时)
- 枚举成员的名称通常是大写字母,以区别于变量
- 枚举类型可以与其他整数类型进行转换,但转换时需要注意值的范围和对齐问题
5.应用
例如给布尔值的0和1取两见名知意的名字😎(实际中会直接用
_Bool)
在嵌入式开发等领域,为节省内存的消耗,不能直接使用文字表示参数,只能用数字表示参数时,给参数命名提高代码的阅读性
二.创建、使用
谨记:枚举变量只是披着文字皮的数字,在枚举体内定义的元素,默认会按照书写的顺序为其附上对应的整数
1.定义
枚举成员默认从0开始赋值,定义时手动指定了某个成员的值,那么后续成员的值会在此基础上递增
(1)定义不改值
-
enum:枚举定义的关键字 -
enumeration_name是枚举类型的名称。 -
enumerator1,enumerator2, ...,enumeratorN是枚举成员,它们所代表的值默认从0开始自动递增赋值,它们代表的其实就是一个个数字
enum enumeration_name {
enumerator1, enumerator2, ..., enumeratorN
};
(2)定义且改值
**概述:**可以改变枚举值的默认值
例子:
enum week //枚举类型
{
mon=3,tue,wed,thu,fri=4,sat,sun
};
2.使用
(1)初始化
**注:**枚举变量的值只能是枚举类型中定义的其中一个
enum 枚举类型名 枚举变量名 = 值;
3.示例
实际编译后,Weekday里面的Sunday...Saturday都会变成0...6的整数
Switch中和Case匹配的,其实也是整数
#include
// 声明一个枚举类型,表示一周中的天数
enum Weekday {
Sunday, // 默认值为0
Monday, // 默认值为1
Tuesday, // 默认值为2
Wednesday, // 默认值为3
Thursday, // 默认值为4
Friday, // 默认值为5
Saturday // 默认值为6
};
int main() {
enum Weekday today = Tuesday; // 定义一个Weekday类型的变量today,并赋值为Tuesday
switch (today) {
case Sunday:
printf("Today is Sunday.\n");
break;
case Monday:
printf("Today is Monday.\n");
break;
case Tuesday:
printf("Today is Tuesday.\n");
break;
// ... 其他情况的处理
default:
printf("Invalid weekday.\n");
break;
}
return 0;
}